
Immer mehr Maschinenbauer bieten ihren Kunden Pay-Per-Use-Modelle an und lassen sich ihre Maintenance-Services bezahlen. Vor diesem Hintergrund gewinnt Predictive Maintenance an Bedeutung. Denn je effizienter die Maschinenwartung, desto weniger Ausfallzeiten und Wartungskosten schlagen zu Buche. Machine Learning Algorithmen können dabei helfen. Die Hintergründe erklärt Julian Mehne, Data Scientist beim Softwarehaus doubleSlash.
Autor: Julian Mehne, Data Scientist bei doubleSlash
Der Service macht den Unterschied. Nur wenn die begleitenden Dienstleistungen stimmen, ist der Kunde auf Dauer wirklich zufrieden. Und wenn ein Maschinenbauer seinen After-Sales-Service monetarisieren oder gar nur die Nutzung seiner Anlagen abrechnen will, dann gilt sein Interesse einer möglichst hohen Performance – zu möglichst niedrigen Kosten. Ziele, die sich nicht zuletzt mit vorausschauender Wartung erreichen lassen.
Das Potenzial ist riesig: So lassen sich laut McKinsey die Ausfallzeiten von Produktionsanlagen um bis zu 50 Prozent und die Wartungskosten um 20 bis 40 Prozent senken. Da kann sich der Aufwand für ein effizientes Predictive Maintenance Modell schnell lohnen.
Kosten senken, Performance steigern
Nicht von ungefähr hat ein großer Automotive-Zulieferer seine Sondergetriebe für Lkw mit einer Predictive-Maintenance-Funktion ausgestattet. Im Fahrzeug verbaute Sendemodule schicken über die Luftschnittstelle permanent Informationen über den Zustand des Getriebes beziehungsweise seiner Komponenten wie Getriebeöl oder Kupplungsscheiben in das übergeordnete Cloud-System. Damit hat der Anwender die relevanten Informationen immer parat. Er kann erkennen, dass alle Parameter im Lot sind oder auch, dass sich Mangelsituationen anbahnen. Daraufhin kann er Wartungen vorausschauend planen, Fahrzeug-Stillstandzeiten verkürzen und Ausfälle vermeiden. Das senkt die Kosten, steigert die Performance und verlängert die Lebensdauer des Getriebes.
Vor allem wenn eine Spezialmaschine – oder wie hier ein Getriebe – in vergleichsweise geringen Stückzahlen, dafür aber weltweit verteilt im Einsatz ist, rechnet sich ein solcher Business Case. Denn erstens macht eine gute vorausschauende Wartung manche Anreise eines Servicetechnikers unnötig. Zweitens wird die Maschine nur dann gewartet, wenn ihr Verschleiß das erfordert. Und drittens schließlich: Muss ein Techniker doch mal anreisen, dann weiß er bereits im Vorfeld, wo der Fehler liegt und gegebenenfalls welche Ersatzteile er vor Ort benötigt.
Kleine Ursache, große Wirkung
Besonders attraktiv wird Predictive Maintenance in Szenarien, in denen eine kleine Fehlfunktion oder ein zu später Eingriff extrem hohen Schaden verursachen kann. Wenn etwa eine Pumpe, die in petrochemische Verarbeitungsprozesse eingebunden ist, Druck verliert, kann schnell ein Dominoeffekt einsetzen: die Temperatur sinkt, das Material wird dickflüssig, verstopft Ventile und bringt den gesamten Prozess zum Stillstand. Im schlimmsten Fall muss in der Folge ein großer Teil der Anlage erneuert werden.
Werden hingegen die Zustandsdaten der Pumpe in Echtzeit übermittelt, schlägt das Predictive-Maintenance-System Alarm, noch ehe es zu solch verheerenden Fehlfunktionen kommt. Dann lassen sich kostspielige Folgen in aller Regel vermeiden.
Die Datenmenge als wesentlicher Faktor
Vorausschauende Wartung lebt davon, dass das führende System Sensordaten auswertet und daraus auf den tatsächlichen Verschleiß des jeweiligen Bauteils und seiner verbleibenden Lebensdauer schließt. Dabei ist der Effekt eines Predictive Maintenance Modells umso größer, je mehr Sensoren in Maschinen und Anlagen Daten liefern. Und: Je genauer das System arbeitet, desto genauer lässt sich bestimmen, wann welche Komponente ausgetauscht werden sollte – rechtzeitig vor einem Ausfall, aber eben auch erst, wenn es tatsächlich nötig ist.
Dazu muss sich das Vorhersagemodell ständig den Gegebenheiten anpassen. Das heißt, die gesammelten Messdaten müssen automatisch interpretiert werden, und die Interpretation sollte sich immer stärker den tatsächlichen Erfordernissen annähern.
Genau das ist die Funktion von Machine-Learning-Algorithmen. Mit ihrer Hilfe lassen sich aus den Daten funktionale Zusammenhänge ableiten, die eine verlässliche Zustandsdiagnose des überwachten Systems und ebenso verlässliche Prognosen erlauben.
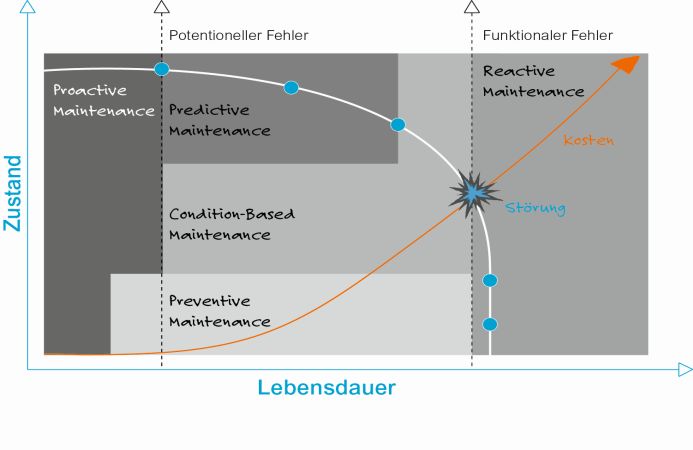
Veränderungen richtig interpretieren
Erstes Ziel ist also eine möglichst treffsichere Vorhersage der nutzbaren Restlebensdauer, der sogenannten Remaining Useful Life (RUL) von Maschinen und Komponenten. Zweites Ziel ist der bereits erwähnte Lerneffekt. Denn damit automatisieren die Algorithmen nicht nur die vorausschauende Wartung. Sie liefern auch adäquate Ergebnisse und gegebenenfalls Handlungsempfehlungen, wenn sich im Verhalten der Maschinen, aber auch in den Rahmenbedingungen Veränderungen zeigen.
Auf dieser Basis lassen sich Wartungsvorgänge, -intervalle und Ersatzteilhaltung optimal an die jeweils aktuellen Bedingungen anpassen. Und das Modell hilft Abweichungen zu erkennen, ehe die Maschine nicht mehr voll funktionsfähig ist oder größere Schäden entstehen. Das kann im Übrigen auch für Schmier- und Verbrauchsmittel angewendet werden. Deren Zustand und Verschleiß lässt sich ebenso überwachen und daraus optimale Wartungs- und Austauschzeitpunkte ableiten.
Datenbasis analysieren
Unternehmen, die ein Predictive-Maintenance-Projekt unter Einsatz von Machine Learning umsetzen wollen, sollten zunächst ihre Datenbasis unter die Lupe nehmen. Optimal ist es, wenn die einzubindenden Maschinen und Anlagen schon seit längerem mit Sensoren ausgestattet und vernetzt sind.
Im ersten Schritt gilt es, die Daten zu sichten und zu bewerten. Interessant ist hier vor allem, welche Zustands- beziehungsweise Messdaten von Maschinen zu bestimmten Zeitpunkten gesammelt werden und seit wann. Auch unstrukturierte Daten wie Bilder oder Audiosignale sollten gesichtet und bewertet werden. Nicht zu vergessen statische Daten wie Firmwareversion, Aufstellungsort der Maschine und Herstellungsdatum.
Wie die Daten gesammelt werden und wie vollständig sie sind, ist entscheidend für ihre Verwertbarkeit. Daten, die nur anhand bestimmter Ereignisse anfallen beziehungsweise erfasst werden, können durchaus hilfreich sein, bessere Ergebnisse aber bringen Daten, die in lückenlosen Messreihen verfügbar sind. Dabei ist auch wichtig, in welcher Frequenz sie gesammelt werden und ob sie sauber dokumentiert sind.
Daten aufbereiten
Entscheidend für den Erfolg eines Projekts ist der nächste Schritt, die Aufbereitung: Die Datensätze müssen bereinigt, falsche Werte gelöscht, fehlende Werte aufgefüllt werden. Zugleich gilt es ein Verständnis dafür zu entwickeln, welche Daten wie und unter welchen Umständen erfasst wurden.
Zu den wertvollsten Informationen zählen Service- und Reparaturdaten. Sie stellen die solideste Basis für eine Remaining Useful Life (RUL) Prognose dar. Denn sie liefern Informationen darüber, welche Maschine wann ausgefallen ist, was defekt war und was repariert wurde. Sofern sich die Servicedaten mit den Zustandsdaten verbinden lassen, ist anhand der Reparaturhistorie ein Abgleich der Zustände vor und nach einer Reparatur möglich. Das Ergebnis sind erste einigermaßen belastbare Aussagen, die zu künftigen RUL-Prognosen führen können.
Nun folgt die Priorisierung der verfügbaren Servicedaten. Sie orientiert sich unter anderem daran, welche Maschinentypen am häufigsten defekt sind, welche Bauteile am ehesten ausfallen und natürlich auch welche Teile im Fall einer Reparatur besonders hohe Kosten verursachen. Die davon ausgehende Ursachenforschung liefert Erkenntnisse dazu, welche Ereignisse oder physikalischen Messwerte zum Beispiel mit dem Versagen eines Bauteils oder einer Maschine korrelieren.
Mit den so gewonnenen Informationen lassen sich die verfügbaren Daten im Hinblick auf die Modellbildung sichten und bewerten. Denn jetzt wird deutlich, was für ein gutes Predictive-Maintenance-Modell relevant sein könnte. In dieser Phase sollten sich die IT-Spezialisten mit Experten zusammentun, die sich mit den Maschinen auskennen.
Ist die grundsätzliche Relevanz der vorhandenen Daten geklärt, gilt es die Fragestellungen zu definieren, anhand derer sich die angestrebten Projektziele am ehesten erreichen lassen. Wichtig ist zu beachten, auf welche Fragen das verfügbare Datenmaterial überhaupt Antworten liefern kann.
Idealerweise genießen in dieser Phase Szenarien den Vorzug, bei denen es um viel Geld geht – also teure Maschinen oder solche, deren Ausfälle besonders hohe Kosten verursachen oder die besonders häufig ausfallen.
Data Scientist einbinden
Ein solches Projekt ist ohne Zweifel vielschichtig und komplex. Um da den Überblick zu behalten, empfiehlt sich die Einbindung eines Data Scientist. Er kommuniziert mit Datensammlern, Entwicklern, Servicetechnikern und anderen Experten, bereitet deren Informationen auf und bringt sie in das Projekt ein. Kurz: Bei ihm laufen alle Fäden zusammen.
Die bis zu diesem Punkt gewonnenen Erkenntnisse sind die Basis für das Erstellen eines „intelligenten“ Algorithmus. Dafür gibt es eine Reihe an guten Tools auf dem Markt. Welche zum Einsatz kommen, müssen die IT-Spezialisten im Projekt anhand ihrer Vorlieben und Vorkenntnisse entscheiden.
Eine gute Grundlage für den schnellen Einstieg sind von IoT-Herstellern bereits integrierte Algorithmen oder vorgefertigte Services wie Azure Cognitive Services oder Amazon AWS AI Services. Allerdings sind diese Tools vergleichsweise unflexibel.
Mehr Handlungsspielraum bieten öffentlich verfügbare KI-Programmierbibliotheken oder Algorithmen-Baukästen. Viele Entwickler greifen beispielsweise auf die interpretierte Sprache Python zurück, um damit schnell ein Modell zu realisieren.
Wer Algorithmen komplett selbst entwickeln will, kann dies mithilfe von Open-Source-Programmbibliotheken wie PyTorch und TensorFlow tun.
Falsche Ergebnisse bedenken
Wie nah eine Vorhersage dem gewünschten Ziel kommt, hängt von vielen Faktoren ab. Entscheidend ist, dass die Folgen eines eventuell falschen Ergebnisses ins Kalkül gezogen und inakzeptable Ergebnisse sicher vermieden werden.
Initiiert das Vorhersagemodell zum Beispiel die Wartung der Maschine, obwohl sie noch gar nicht erforderlich wäre, so ist das ein falsch-positives Ergebnis, das zwar unerwünscht, aber noch akzeptabel ist. Erfolgt die Wartung zu spät und die Maschine fällt aus (falsch-negatives Ergebnis), dann mag das bei überschaubaren Folgen noch akzeptabel sein, auf keinen Fall jedoch bei einer Flugzeugturbine oder einer Pumpe, wie sie im obigen Beispiel genannt ist.
Fazit: Unternehmen, die mit vorausschauender Wartung ambitionierte Ziele verfolgen, müssen Künstliche Intelligenz beziehungsweise Machine Learning einbinden. Denn erst mit KI lässt sich das Wertschöpfungspotenzial von Predictive Maintenance optimal ausschöpfen.(ag)
Kontakt zu doubleSlash
doubleSlash Net-Business GmbH
Leitzstraße 45
70469 Stuttgart
Tel.: +49 711 / 2094920
E-Mail: info@doubleSlash.de
Website: www.doubelslash.de
Ebenfalls interessant:
https://industrie.de/kuenstliche-intelligenz/interview-juergen-bock-kuenstliche-intelligenz-kuka/






{kind=link}